What this is about: Most teams think the hard part of the EU AI Act is writing the documents. It is not. The hard part is keeping everything connected and current every time your AI changes. This explains why, in plain English, and what to do about it.
AI Act Compliance for Medical Devices is not a one-time documentation exercise. It requires keeping evidence, risk, testing, and technical documentation aligned as your AI evolves.
Part 3 of 3 in our plain-English EU AI Act series. Part 1 explains the Act and what August 2nd really means. Part 2 helps you check if your AI product is “high-risk.”
The trap: thinking this is a one-time job
Here is the comforting story teams tell themselves. “The AI Act needs a pile of documents. We will hire a consultant, run a sprint, write the risk file, the data dossier, the technical file, and the monitoring plan. Then we are done.”
The documents part is real, and it is finite. You really can produce a clean set of paperwork for your first conformity assessment (the check that gets your device its CE mark). Many teams will do exactly that and feel finished.
They are not finished, and this is the single most important thing to understand about the AI Act: an AI medical device is a moving target. Unlike a steel scalpel, it keeps changing after launch. The law does not just want your documents to exist. It wants them to stay true.
Why AI products never sit still
Over a normal lifecycle, an AI device changes constantly:
- the model gets retrained or fine-tuned,
- the data gets refreshed, expanded, or re-labelled,
- the software ships new releases (your code and third-party components),
- the intended use or performance claims get refined,
- risk gets re-scored as real-world signals come in,
- testing (verification and validation) gets repeated against the new state,
- monitoring picks up drift, edge cases, and complaints,
- CAPA (corrective and preventive action, your formal “fix it and stop it happening again” process) opens to deal with them,
- and the Technical File has to be updated to match all of it.
Now here is the part that catches people out. None of these moves alone. Every change ripples.
Retrain the model and you have not made one change, you have triggered a chain reaction: a new data record, a fresh risk assessment, another round of testing, a technical file update, a question about whether this counts as a “substantial change” you must report to your notified body, and a monitoring plan with a new baseline. Update one dataset and the same chain fires. Patch one third-party software component and your software lifecycle records, risk file, and cybersecurity controls all need another look.

What an auditor will actually ask
This is where the real test lives. A notified body or auditor will not just ask “do you have a risk file?” Anyone can produce a file. They will ask the harder question:
Show me that your testing evidence, your risk assessment, your data record, and your technical file all describe the same model version that is on the market today.
That single question is the whole game. It is not about whether you wrote things down once. It is about whether everything still lines up, right now, after every change you have made.
Why scattered tools quietly break the chain
Now picture the typical setup in a busy small company:
- the procedures live in SharePoint,
- the risk file is an Excel workbook on someone’s laptop,
- CAPA happens over email,
- test reports sit in a project folder,
- and the technical file is a binder someone assembles by hand.
Each of these is fine on its own. The problem is that nothing is linked. There is no connection between the risk row, the test report, the email thread, and the technical file page. So every time your AI changes, a human has to remember to update each separate place by hand.
And the moment one update gets missed, the chain breaks silently. Nobody gets an error message. The risk file still says version 3 while the live model is version 4. The technical file still describes the old data. The documents all still exist. But they no longer agree with each other, or with what is actually shipping.
That is the quiet failure mode of the AI Act. Not “we have no documents.” It is “our documents drifted out of sync as our AI changed.” The paperwork is there. The control is gone. And control is exactly what you have to prove.
What “connected evidence” actually means
Connected evidence is the fix, and the idea is simple. Instead of separate files that someone has to keep in sync by hand, every record is linked to the records it affects.
In a connected system, a model update, a dataset change, or a software release is treated as a controlled event. That event is automatically tied to the risk it changes, the testing it requires, the CAPA it might open, the change control that governs it, the monitoring it feeds, and the technical file entry it updates. The evidence is a web of links, not a pile of folders.
Two things follow from that, and they are the whole value:
You can see the ripple. When you start a change, the system shows you every linked record that now needs review. Instead of hoping a person remembers all ten places, you see the blast radius. That is what event-driven QMS and proper CAPA and non-conformance workflows are built to do.
You can answer the auditor instantly. Because the risk file, the testing, and the technical file are already linked to the live model version, you do not assemble proof under pressure. The links are already there. You can show, on any given day, that the product is still under control.
The AI Act did not invent the need for traceability. It just raised the stakes, because an AI device changes far more often than a traditional one, and every change has to stay provably connected.
The takeaway from Part 3, and from this whole series: doing the paperwork once is the easy part. Keeping everything connected and current as your AI keeps changing is the real job. Solve the connection problem early and your conformity assessment becomes a report you run, not a fire drill you survive.
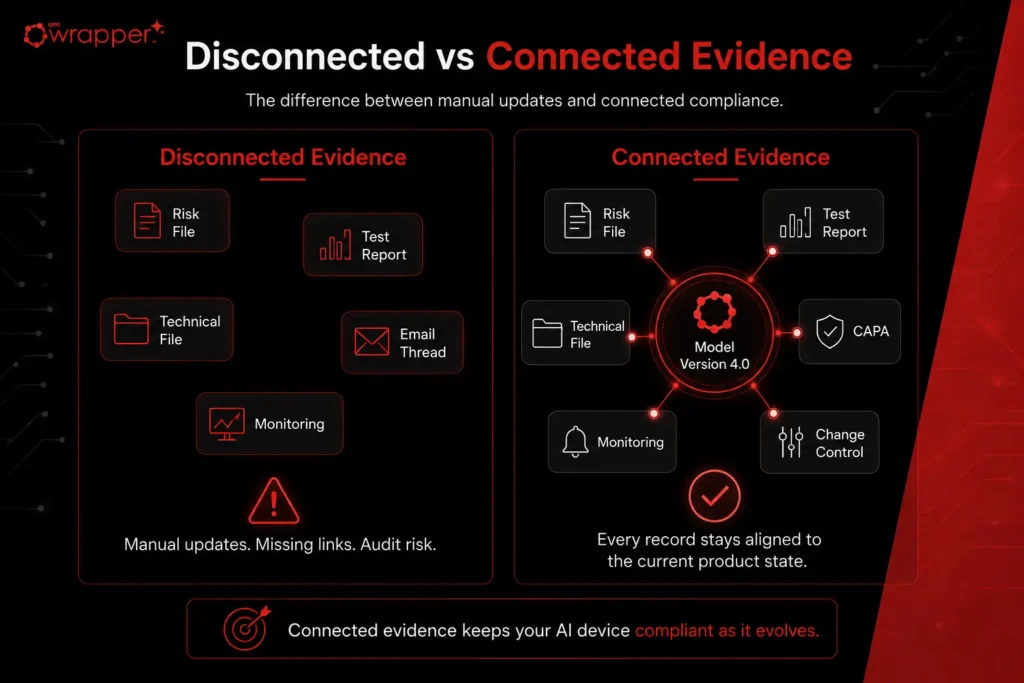
How qmsWrapper fits in
This is the exact problem qmsWrapper is built for. It is a connected Medical Device Compliance QMS where a model update, dataset change, or software release is a controlled event, automatically linked to the risk, testing, CAPA, change control, monitoring, and Technical File it touches. When you start a change, it surfaces every record that now needs review, and when an auditor asks you to prove the current model version is fully controlled, the evidence is already linked and current. See AI QMS for medical devices, or book a qmsWrapper demo to see connected change impact for an AI device.
What Medical Device Teams Need to Know About Ongoing AI Act Compliance
Why is staying AI Act compliant harder than achieving it once?
Because an AI medical device keeps changing. Models get retrained, data gets refreshed, and software ships new releases, and each change ripples through risk, testing, monitoring, CAPA, and the Technical File. The standard is not “did you document it once,” it is “is your evidence connected, current, and consistent across every change.”
What will an auditor or notified body actually check?
Beyond whether documents exist, they check whether everything agrees. A typical hard question is: prove that your testing, risk assessment, data record, and technical file all describe the same model version that is live today. If your records drifted out of sync, you cannot answer it.
Why do SharePoint, Excel, and email break AI Act compliance?
Not because the tools are bad, but because nothing is linked. When a change happens, a person has to update each separate place by hand. Miss one update and the chain breaks silently, with no error and no warning, so your records no longer match what is actually shipping.
What does “connected evidence” mean?
It means every record is linked to the records it affects. A model or data change is a controlled event tied to the risk, testing, CAPA, change control, monitoring, and technical file it touches. Instead of syncing files by hand, the connections are built in, so the evidence stays consistent.
What is change impact analysis?
It is the system showing you every linked record a change affects before you make it. When you start a model retrain or a data update, you see the full “blast radius”: the risk items, the tests to re-run, the procedures and training affected, and the technical file sections that go stale. It replaces hoping a human remembers everything.
Does keeping evidence connected also help with human oversight?
Yes, indirectly. A connected system keeps a person in control of every change: a human reviews, approves, and signs off, with a clear record of who did what. That human-in-control posture lines up well with the AI Act’s human oversight expectations for high-risk systems.